
Document clustering is one of the key modules in Visual Text Analytics. The goal of document clustering is to group similar documents without having any prior knowledge about their labels. Document clustering has many applications in different fields from news trends to health analytics. It is also a very important first step for other visualizations and mining strategies. Despite numerous text clustering algorithms and also statistical techniques to measure the quality of clusters, user-supervised clustering is preferred to totally unsupervised clustering in analytic applications. However, the user requires presenting documents and collecting feedbacks require an interactive clustering algorithm with easy to learn parameters as well as a well-designed visualization platform.
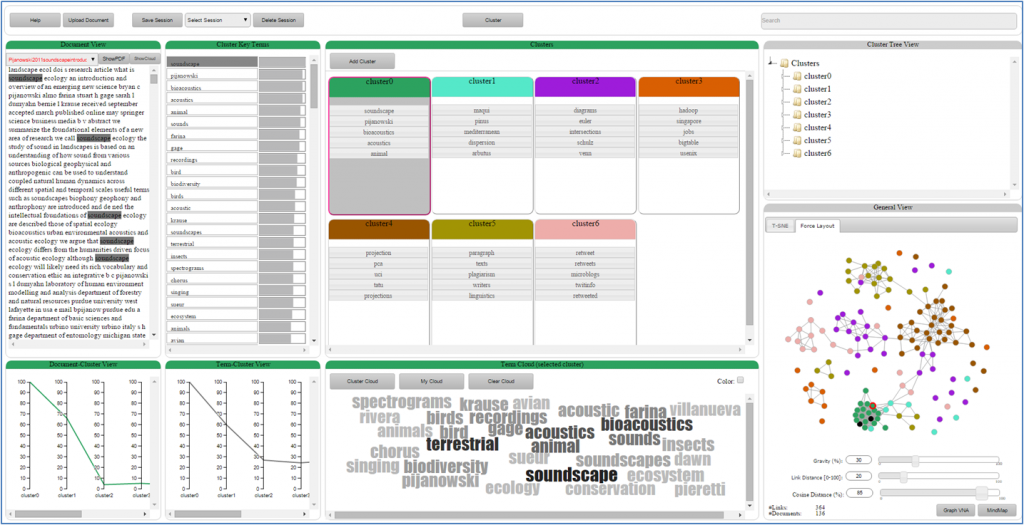
Keyterm-based clustering approaches are arguably very intuitive for the users to guide text clustering process and adapt clustering results to the various applications in text analysis. Its way of markedly influencing the results, for instance by expressing important terms in relevance order, requires very little knowledge of the algorithm from the user and has a predictable effect, speeding up user-guided clustering. In this project, we present a visual approach to support interactive key term-based clustering. Visualizations are provided for the whole collection as well as for detailed views of document and cluster relationships.
Publications:
- A Visual Approach for Interactive Expertise Finding and Exploration
E Sherkat, S Nourashrafeddin, R Minghim, E MiliosCIKM 2016 Workshop on Data-Driven Talent Acquisition (pdf)
Click here to have an access to the online demo of the system and get more information.